MediaPipe 是 Google Research 所開發的多媒體機器學習模型應用框架,透過 MediaPipe,可以簡單地實現手部追蹤、人臉檢測或物體檢測等功能,這篇教學將會介紹如何使用 MediaPipe。
原文參考:使用 MediaPipe

MediaPipe 是 Google Research 所開發的多媒體機器學習模型應用框架,支援 JavaScript、Python、C++ 等程式語言,可以運行在嵌入式平臺 ( 例如樹莓派等 )、移動設備 ( iOS 或 Android ) 或後端伺服器,目前如 YouTube、Google Lens、Google Home 和 Nest...等,都已和 MediaPipe 深度整合。
前往 Mediapipe:https://google.github.io/mediapipe/

如果使用 Python 語言進行開發,MediaPipe 支援下列幾種辨識功能:

Jupyter 本身是一個 Python 的編輯環境,如果直接安裝 mediapipe 可能會導致運作時互相衝突,因此需要先安裝 mediapipe 的虛擬環境,在上面安裝 mediapipe 後就能正常運行,首先建立一個資料夾 ( 範例建立一個名為 mediapipe 的資料夾 ),如果是 Windows 輸入 cmd 開啟「命令提示字元視窗」( Windows 輸入 cmd ),Mac 開啟終端機,輸入命令前往該資料夾 ( 通常命令是 cd 資料夾路徑 )。
如果是本機 Python 環境,可直接略過這個步驟 ( 本機環境建議參考「使用 Python 虛擬環境」以虛擬環境進行安裝 )。

進入資料夾的路徑後,輸入下列命令建立 mediapipe 虛擬環境 ( 下方的 mediapipe 為虛擬環境的名稱,後方 python=3.9 是要使用 python 3.9 版本 )。
conda create --name mediapipe python=3.9
建立環境會需要下載一些對應的套件,按下 y 就可以開始下載安裝,出現 done 就表示虛擬環境安裝完成。
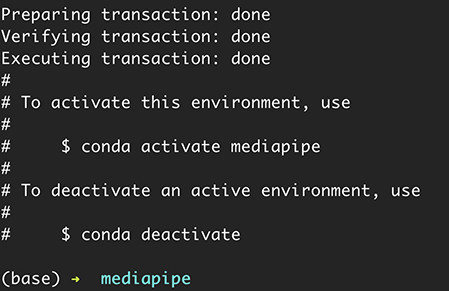
輸入下列命令,就能開啟並進入 mediapipe 虛擬環境,這時在命令列前方會出現 mediapipe 的提示 ( 輸入指令 conda deactivate 可以關閉當前虛擬環境 )。
conda activate mediapipe

進入 tensorflow 虛擬環境後,輸入下列指令,在虛擬環境中安裝 Jupyter,經過自動安裝一系列套件的過程後,出現 done 表示成功安裝。。
conda install jupyter notebook
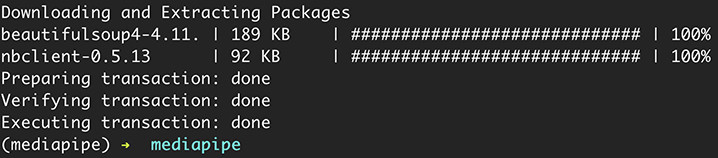
輸入下方指令,安裝 mediapipe。
如果是使用本機 Python 環境開發,建議參考「使用 Python 虛擬環境」以虛擬環境進行安裝,並先使用命令
python -m pip install --upgrade pip將 pip 升級,避免讀取 mediapipe 模組時發生找不到模組的錯誤 ( no module named 'mediapipe' )。
pip install mediapipe
輸入下方指令,安裝 tensorflow。
pip install tensorflow
輸入下方指令,安裝 opencv。
pip install opencv-python
開啟 Anaconda,選擇切換到 mediapipe 的環境 ( 就是剛剛建立的 mediapipe 虛擬環境 )。
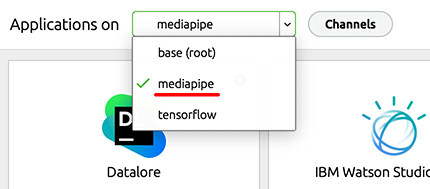
切換環境後,開啟 tmediapipe 環境下的 Jupyter,啟動能開發 mediapipe 的環境。

新增一個 Jupyter 的專案,輸入下方的程式碼,執行後如果沒有問題,就可以從攝影機即時偵測人臉。
import cv2
import mediapipe as mp
cap = cv2.VideoCapture(0)
mp_face_detection = mp.solutions.face_detection
mp_drawing = mp.solutions.drawing_utils
with mp_face_detection.FaceDetection(
model_selection=0, min_detection_confidence=0.5) as face_detection:
if not cap.isOpened():
print("Cannot open camera")
exit()
while True:
ret, img = cap.read()
if not ret:
print("Cannot receive frame")
break
img.flags.writeable = False
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = face_detection.process(img)
img.flags.writeable = True
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
if results.detections:
print(len(results.detections))
for detection in results.detections:
mp_drawing.draw_detection(img, detection)
cv2.imshow('oxxostudio', img)
if cv2.waitKey(1) == ord('q'):
break # 按下 q 鍵停止
cap.release()
cv2.destroyAllWindows()

大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我已經寫了超過 400 篇 Python 的教學,有興趣可以參考下方連結呦~ ^_^


 iThome鐵人賽
iThome鐵人賽